The process of releasing software in a timely manner is highly business critical. Especially, the mobile release process is critical when moving towards a mobile-first strategy. The talk “Hacker Way: Releasing and Optimizing Mobile Apps for the World” (by Chuck Rossi @Facebook’s f8 conference in 2014) describes how Facebook turned its organization structure. This move was necessary to reflect the importance of mobile for Facebook’s future. Chuck heads the company’s release team and is responsible for all releases.
Impact of Mobile strategy on organization
Before re-prioritizing everything within Facebook and focusing on mobile the development team was organized mainly around channels:
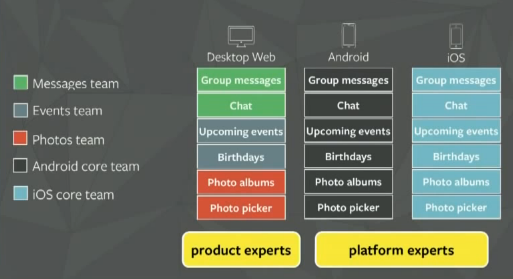
This developer distribution led actually to heavy prioritization problems. The different product teams with focus on Desktop Web did prioritize their topics coming up with a numbered list of items. This prioritization were then handed over to the platform experts. They had the problem of seeing number #1 priority item of the “Messages team” competing with number #1 priority item of e.g. the “Events team”.
Facebook came over this organization issue by organizing their development differently: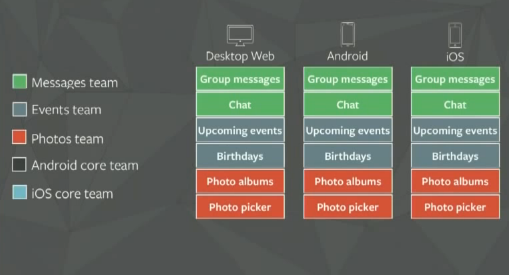
Now, the Facebook engineering team has product and platform experts mixed working on features across all platforms.
Software Releases at Facebook
Facebook has some simple rules – simple but made of stone:
- WE SHIP ON TIME
A release can not be postponed. If a feature can’t make it it will not make it into this release.
- MAKE USERS NO WORSE OFF
Facebook is data driven. KPI’s are watched thorougly after a release. If they don’t develop as expected, a change needs to happen (e.g. fix forward or modification).
- THERE’S ALWAYS THE NEXT ONE
Since the releases are already dated there is always the next release. If you can’t get your feature in today, it will be part of the release tomorrow. This relaxes the overall organization and takes away a lot of the pain experienced when the next release is month away.
- RETREAT TO SAFETY
The release team is responsible for delivering a stable product. When the team actually picks the ready developed items (30 to 300 on a daily release) they carefully take the stories into the release candidate. It’s described as “subjective”. They follow a simple rule when building the release package: “If in doubt, there is no doubt”.
Facebook releases their web platform following a plan:
Sunday, 6 p.m. the release team tags the next release branch. That’s done directly from the trunk. The release branch is stabilized until Tuesday, 4 p.m. and then released as a big release including 4000 to 6000 changes – 1 week of development. On Monday, Tuesday, Wednesday, Thursday, Friday, Facebook does two releases a day. These are cherry-picked changes – around 30 to 300 each release.
For Mobile the plan differs obviously a bit: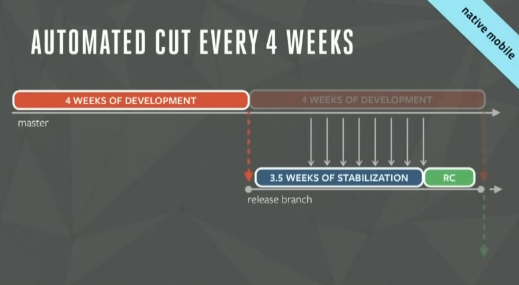
On mobile the overall release principle is actually the same as described above. The development cycle is 4 weeks – on the day the previous release gets shipped to the various app stores, the next release candidate is taken from the master. The candidate is then 3,5 weeks into stabilization. Each candidate includes further 100-120 cherry picks taken during this 3 weeks stabilization period. When stabilization is over, the Release Candidate is tested and not touched any more.


 The really great blog
The really great blog