Page load time is crucial. Business and technology people as individuals start understanding the importance of this topic almost immediately and are willing to support any effort to get fast pages out of your service.
But how can you foster a culture of performance and make people aware of the importance of this single important topic – amongst hundred other important topics?
That was one of the challenges early 2013. Management and myself were convinced that 2013 one of our key focus topics is around web performance.  The birthday of “T4T”. The acronym stands for …
The birthday of “T4T”. The acronym stands for …
- Two – Deliver any web page within 2 seconds to our customers.
- 4 – Deliver any mobile web page within 4 seconds to our customers over 3G.
- Two hundred – Any request over the REST API is answered below 200 milliseconds.
So, early 2013 we started T4T as an initiative to bring our page load times down to good values. To measure the page load time we experimented with two tools: Compuware’s Gomez APM tool and New Relic’s APM tool. Gomez was used initially for our Java based platform and New Relic for our Ruby on Rails platform. But we were able to measure and track-down some really nasty code segments (i.e. blocking threads in Java or 900 database requests in Ruby where 2 finally did the same job).
How did we get the idea of T4T into the organization? Any gathering of people with presentation character was used to hammer the message of web performance to the people. Any insight on the importance, any tip, hint, workshop, conference, article, blog post, presentation, anything was shared with the team. Furthermore, T4T was physically visible everywhere in the product development department:

THE LOGO – visible … everywhere … creepy!

T4T logo and information on page load and web performance at the relax area for software developers and product owners …

T4T at the VP office door.
For me, especially the endless talking about the topic, raising the importance, questioning of e.g. JPG picture sizes, special topic discussions on CSS sprites vs. standalone images or the usage of web-fonts for navigation elements helped a lot to raise the curiosity of people. Furthermore, giving them some room and time for research work helped a lot.
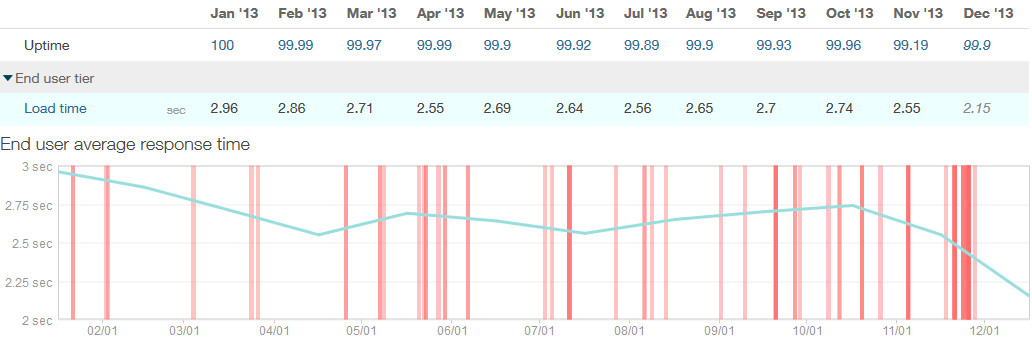
What did we achieve? Well, one of our platforms – based on Ruby on Rails started with page load time of 2,96s in January 2013. End 2013, the platform was at an impressive 2,15s page load time. In the same time, the amount of page views increased by factor 1,5!
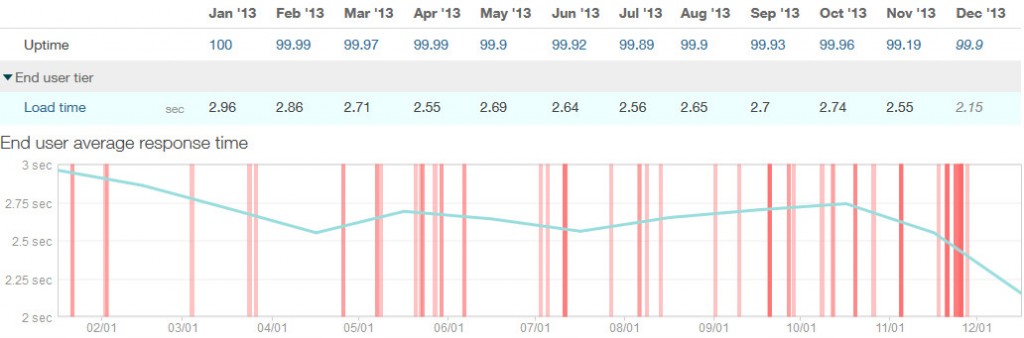
Page Load time over the year 2013
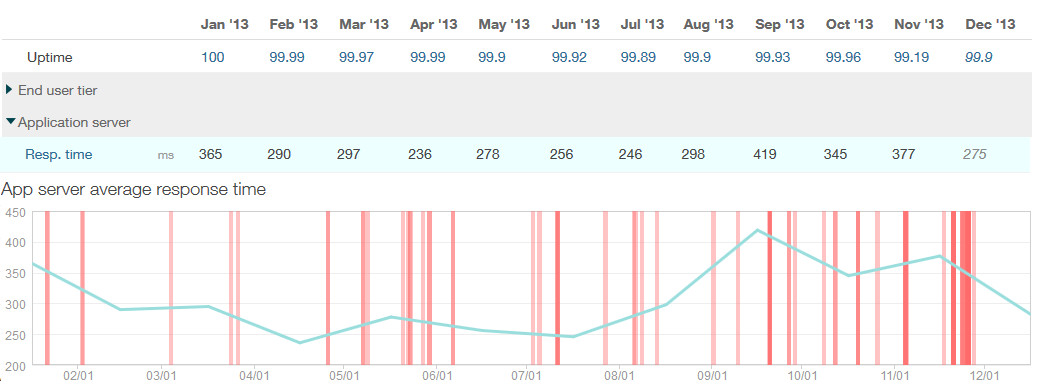
During the same time period, the App server response time dropped from 365ms to 275ms end of year – this time doubling the amount of requests in the same time.
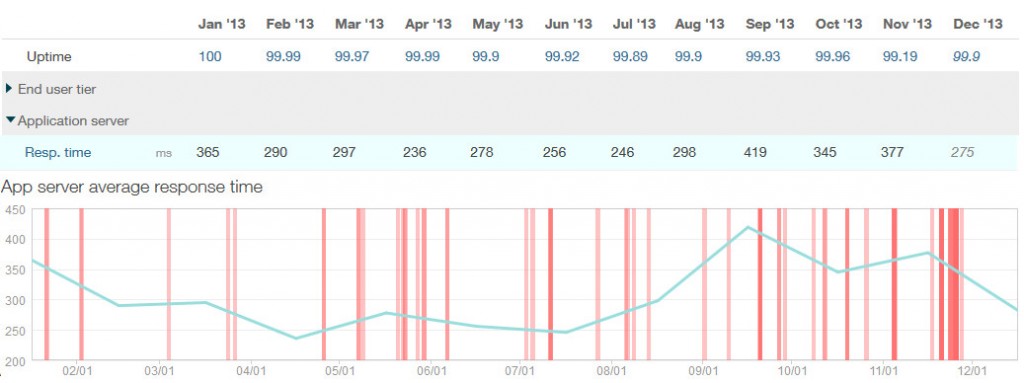
App server response time over the year 2013
Most interesting, we had one single release with a simple reshuffling of our external tags. Some of them now load asynchronously – or even after the onLoad() event. This helped us drop the page load time from around 2,5s to 2,1s – 400ms saved!
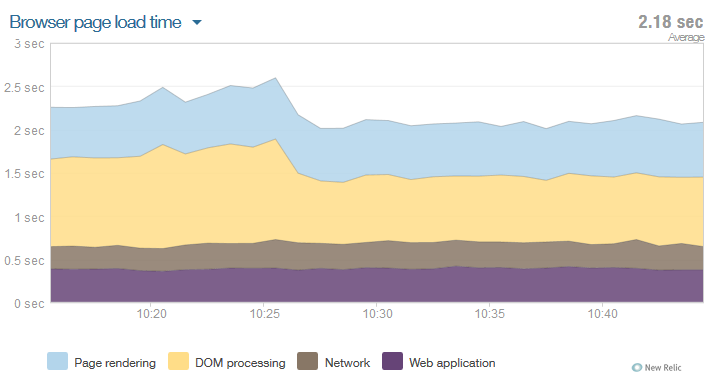
Impact of one single release and the move of adtags after the onLoad() event.
So, my takeaways on how to foster such a performance culture?
- You need a tangible, easy to grasp goal!
- Talk about the topic and the goal. Actually, never stop talking about this specific goal.
- Make the goal visible to anybody involved – use a logo.
- Measure your success.
- Celebrate success!
- Be patient. It took us 12 month …

 The really great blog
The really great blog