
Customer & Service Provider interface … epic fails and how to overcome them
In a recent post I was talking about an interesting situation regarding the collaboration with our service provider (see https://www.agile-minds.com/customer-service-provider-epic-fails/). After some weeks I’d like to take a chance to draw some conclusions and report back some successes and learnings. I definitely see some silver lining on the horizon regarding the collaboration part – but also discovered some real black holes within our organisation. It’s always the same: process insufficiencies will always show up – latest – in the IT department …
The Modified Setting
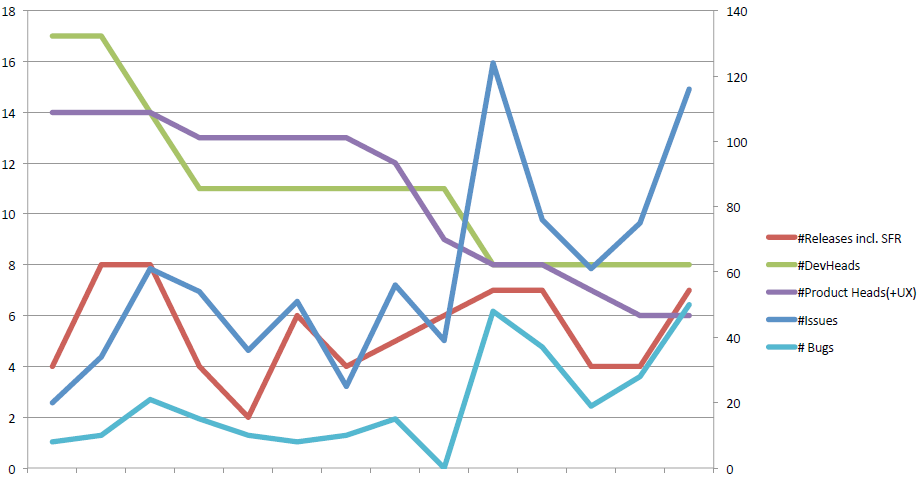
Now in the development partnership with our service provider we pay for 2,5 software developers + 0,75 project management person. This means we added significant ressources to the aspect of project planning, communication and management.
Our project management person and the pendant at the service provider really met twice a week to discuss progress, issues and need for further planning on specific tasks. In addition to that it’s me and the general manager of the service provider meeting almost weekly to discuss issues and problems. This approach helped to improve the communication a lot. We’re now in a continuous dialog. Understanding of each other has raised enormously. A great step!
The New Situation
We are still not happy with the outcome – but the reasons have changed dramatically. Previously, we as an organization were not able to articulate our needs and get this information over to our service provider. We changed our communication paradigm and introduced the face-to-face communicaion twice a week. Now, the service provider has a ways better view of our requirements and is eager to start implementation. However, a lot of our stories lack quality from a subject matter view. How did we come to this point?
Multiple stakeholders talking to the service provider – We only have one person talking about new requirements – our project manager. He’s responsible to collect requirements in-house and communicate them back to our service provider. This works quite good. We’ve setup internal bi-weekly calls to collect and prioritize requirements. We’ve had our first quarterly face-to-face meeting where we started to build and organize the company backlog.
No clear communication of priorities, requirements and goals – Flag it as solved with the previous point.
Fundamental changes in design after going live – This is still an ongoing topic. But it’s a question of educating our internal people. Since we’ve one single person doing the communication towards the service provider it’s one of his duties to explain people that if there’s a change in requirements after going live we’ll treat this change as a new requirement – and this needs to get prioritized and implemented. Education.
The New Symptoms
No progress over all – Nope. Having progress. Or eager to go on. But …
Bad requirement quality – This was not transparent so far. But it came up when we introduced the new way of working. It became clearer and clearer that our subject matter experts – the stakeholder – didn’t exactly know what they wanted – not even at the point when they were talking to the service provider. Or they knew what they wanted – but didn’t consider the other business units in the design phase.
The Idea … did work out so far
The two aspects I’ve decided to implement
- Setting up a stable and reliable single face of contact on working level
- Introducing basic agile principles to get to stable requirements
worked out smoothly so far. As usual the introduction of agile aspects increased transparency of involved processes and especially the quality of the different artifacts a lot. And new issues turned up.
Quality of Requirements
As said previously the introduction of agile principles – well, I’d say of new communication patterns – produced process insufficiencies of our own organization.
Silo thinking – our business is separated in different business units. The different units have their own targets and try hard to reach them. There is no competition between the units – but everybody takes care of their own business. Two of the business units eventually use the same instance of the student information system. Especially between those units we have a lot of cases where e.g. the layout of the exam certificates differs, rule sets for course acceptance differ, specializations of courses differ and so on. Small differences – which might be needed … or not – which have a big, big impact on implementation capacities. It’s a difference to create different rule sets for courses – double the implementation work. And why? Ah, the business stakeholder didn’t have time to discuss their individual needs and combine them into mutual needs.
Low quality – not well thought-out – Another point we found is the quality and depth of the various business requirements. A lot of our business requirements arrive at our project manager at a stage where it says “We need a proper implementation of …”. Well, what does “proper” mean? Many times we experience developers from the service provider receiving last-minute changes – still. That’s one of the focus points for future improvements.
No consistent prioritization – Our exec management wants to review the implementation prioritization. Fair enough. We’ve agreed on having a call/meeting every second month. In this call we’ll run through the company backlog and listen carefully to what exec management sees as top priorities. In parallel we have our working calls with the business stakeholder every second week. Together, I believe, we’ll arrive at a prioritization which puts most important topics first.
My biggest learning out of this so far?
No matter how big the issue – start introducing agile patterns. Here especially the communication, company backlog and the face-to-face meeting helped a lot to unveil the real issues behind the “bad customer / service provider” interface.
The nice part about the agile pattern is the transparency. It automatically points you to the real pain points – through transparency.
Stay tuned and read on – to be continued.