Foreword to my notes on Marty Cagan’s workshop “How to Create Tech Products Customers Love”
Here’s my foreword for a series of 11 posts summarizing my personal notes from Marty Cagan’s workshop “How to Create Tech Products Customers Love”. From 5th to 6th of June 2019 I attended the workshop by Silicon Valey Product Group (https://svpg.com/) „How to Create Tech Products Customers Love” in San Francisco (https://svpg.com/workshops/). The workshop was held by Marty Cagan himself.
I met Marty in 2012 already during my time as CTO at the German dating site “FriendScout24” where his advice turned out to be really valuable for our product development teams – and myself. Marty’s knowledge and personality stayed in good memory – since then.
My motivation to visit the workshop by Marty Cagan in San Francisco
To continue my continuous learning journey I booked myself privately into Martyworkshop to catch up on digital product development
For networking reasons I decided to go to San Francisco to have Silicon Valley people around me
Value for money – is the investment worth it?
I found the workshop to be worth every cent because it’s simply not enough to read the book. Serious product people should attend the workshop, ideally more than just one person from the organization
Especially, the information shared between the lines is valuable, unique and really helpful
Questions from the audience reflect your own level of expertise in this field
Marty’s individual answers help to solve unique problems not covered in the book or his blog
Preparation for the workshop
As a preparation I read the latest edition of Marty’s book “Inspired”.
I decided to put my notes onto my blog to keep it preserved for my further reference. The notes in isolation don’t make too much sense. However, in combination with the book and the workshop my notes provide a lot of information between the lines. The handout for the workshop is only available in combination with the workshop.
The notes are quite comprehensive and I decided to split them into multiple blog entries for further reference. The split follows the structure of the workshop – and partially the book.
These notes of Marty Cagan’s workshop “How to Create Tech Products Customers Love” introduces Marty himself and talks about root causes of product failures.
Introduction
The way Marty successfully builds digital products is influenced by multiple methods and techniques. He describes himself as “only collecting technologies and methods which just worked at other places”. He sees himself as an evangelist for methods.
For him key influencing methods / approaches are:
Customer Development
Lean Startup Techniques
Product Discovery Techniques
Product Analytics
Lean UX Techniques
Design Thinking
Agile Methods
The origin
of the overall workshop is from Marty’s time at Netscape. At the time the
browser war was still open and it turned out that the common way of developing
products – the way Microsoft did it at the time – didn’t work for the internet
age any more. Most interestingly, most of the basic principles were defined at
Marty’s Netscape time and were altered slightly until today.
“big bang” releases are those happening less frequent than every two weeks.
Root Causes Of Product Failure
Why product development typically fails?
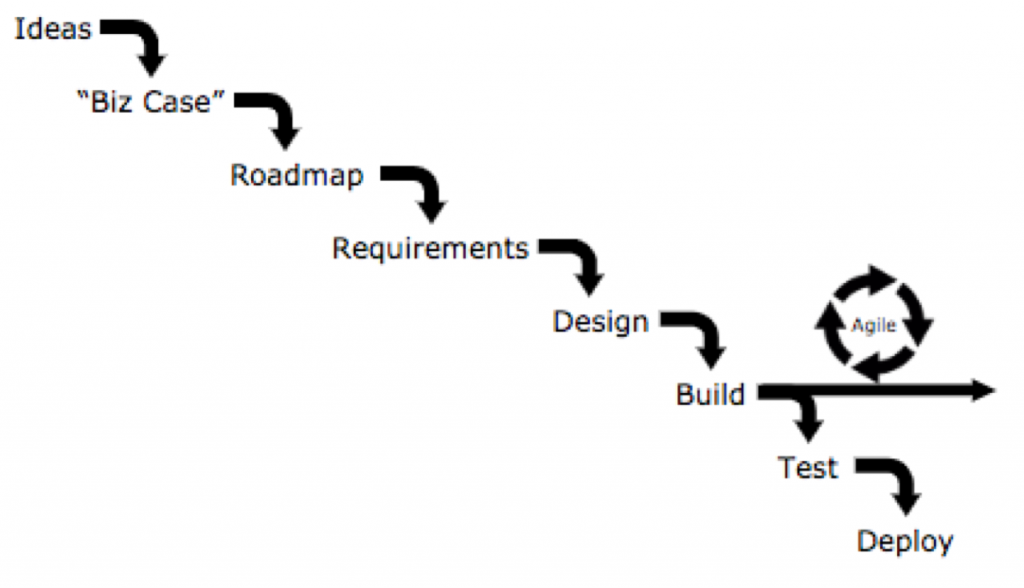
From Idea to Delivery in WATERFALL process
IDEAS – The source of ideas
Typically, the source of ideas are customers, managers and other stakeholder of the product. These groups of people typically don’t know what’s possible to do today from a technology perspective. Furthermore, they don’t really know what they want or need until they see it. Hence, great companies involve their tech people in the idea generation process. They typically are the best source of innovation.
Apple
builds tons of prototypes to lower the risk of failure building a device (e.g.
iPhone).
BIZ CASE –
Business Case Fallacy
The
business case is positioned too early in the overall process. At such an early
time in the process nobody has a proper idea on cost to implement the idea nor
any idea on the benefit. All information is based on guessing or experience, no
evidence on the assumptions can be provided at this time.
PRODUCT
ROADMAP
Typically, the product roadmap is confused with a committed list of features. Two reasons for the existence of roadmaps:
The leadership team of a company
wants to ensure the teams are working on the most important topics
They want to know when it’s due for
delivery
The BING
team at Microsoft confessed they’re “only” able to ship 10% of their roadmap
items “on time”.
Why’s that?
Roadmaps are not trusted by
stakeholders because they don’t deliver on time
It takes 3-4 iterations until the
items on the roadmap actually provide value – the “time-to-result” is ways more
important than the “time-to-market”
Roadmaps are prohibitive to reach
the real product goals since they’re too focused on features
But
customers always ask for product roadmaps. What to do? Customers usually don’t
want to have feature roadmaps, they want to get an understanding of the future
product vision, where is it heading to?
REQUIREMENTS
– The Role of Product
The typical
requirement gathering job is no longer relevant in modern product development.
The job of a Product Owner (as known from agile) is typically 5-10% of the role
of a Product Manager. PO is the operative job working with the agile team in
delivery. The PO and the PM need to be the same person.
The real
work of product teams is not to optimize existing features, but to innovate, to
create new solutions to specific business problems. The methods presented in
the workshop aim to deliver winning products faster. Not through longer work
hours, but a smarter and more predictable way.
DESIGN –
The Role of Design
Design is referred
to as UX, visual design, experience design. Typically, in waterfall models
design is brought into the process ways too late. The waterfall-model enforces
the “lipstick-on-the-pig”-model and is doomed for failure.
In the
waterfall product development model the only place for agile methods is during
build and test. It only lives in the engineering department.
DEPLOY –
Output not Outcome
The whole waterfall process is tailored to deliver output and not outcome.
DEPLOY –
Customer Validation Too Late
In the waterfall product development process the customer sees the product only after it’s deployed. Customer validate it by accepting or neglecting the product. The opportunity cost with this approach are extremely high and dangerous for the overall business!
The whole
process takes way too long to validate the overall effort of building the
product. Building a MVP which takes 4 month is ways too long. A startup needs
50-100 iterations to have a successful version ready for market fit. Typically,
a MVP takes 4 hours to a few days. Microsoft has a patient leadership team. It
takes typically 4-8 years to launch a product and 4-6 iterations until the
product is really great (e.g. Internet Explorer, Bing, …).
“It’s not about processes; don’t be religious about process. It’s the outcome to focus on.”
“The riskiest thing you can do is not to take risks.”
Diane Greene
Tackle risks up front – as early as possible. In digital product development there are four risks to address:
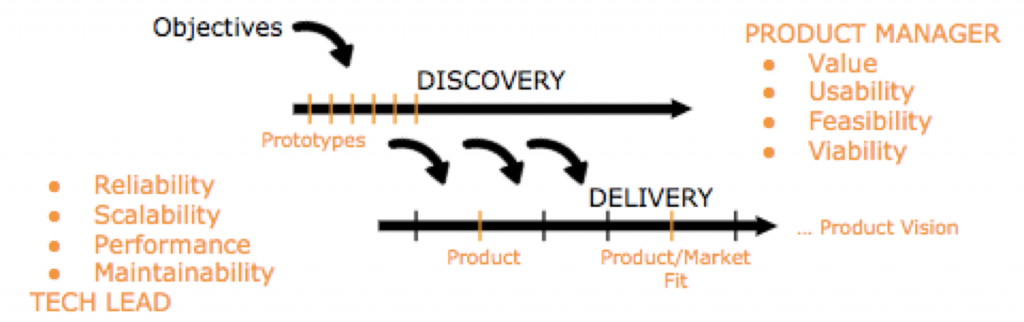
[HARD] VALUE risk – will they use / buy it?
[SOLVED] USABILITY risk – can they use it?
[SOLVED] FEASIBILITY risk – can we build it?
[HARD] BUSINESS VIABILITY risk – will our stakeholder support it? Will it work for the business?
The value risk and the business viability risk are hard to tackle, usability and feasibility however are covered with methods and tools.
It’s the job of the product manager to address these risks before engineers build the product.
2) COLLABORATION
“To innovate you need to collaborate.”
Marissa Mayer
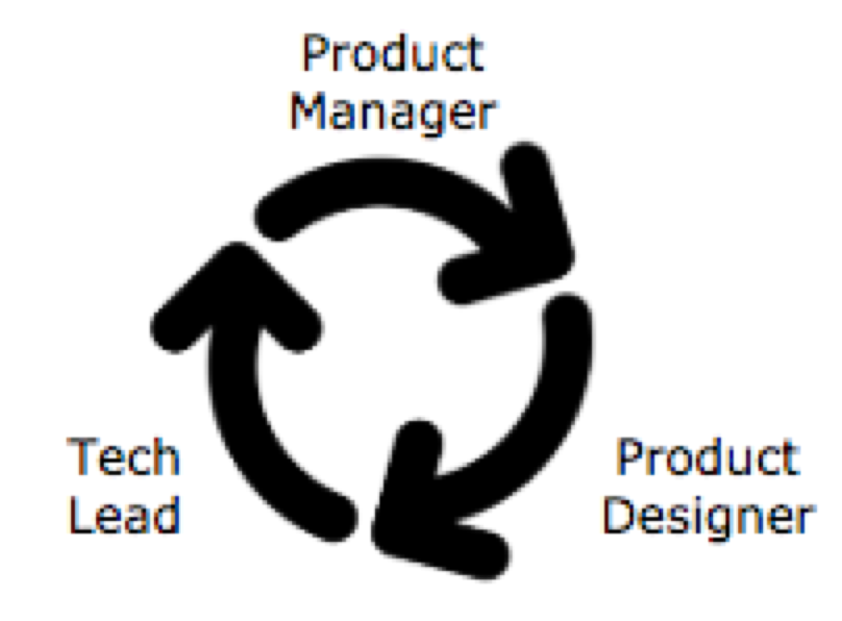
The core of the collaboration: Product Manager, Product Designer and Tech Lead
Define products collaboratively, not sequentially. It is a big advantage to have teams geographically collocated – sitting in the same room ideally. If that’s not possible for whatever reasons the minimum setup is to have the Product Manager, the Product Designer and the Tech Lead at the same location. All other models simply don’t work.
Most times the innovation is driven by engineering (e.g. iPhone). A good example for all-on-site is balsamiq. A good example for all-off-site is Invision. Invision is a organizational setup where all people work remote – it’s part of the DNA. In this case, the distributed Product Manager / Product Designer / Tech Lead works – because of the culture of the company.
3) RESULTS
Focus on business results, not output. Performance is measured by results.
“As a venture capitalist, we don’t care how many features were shipped last quarter or last year. Instead, we look at the business results, and whether the team is building a product that customers love.”
Ha Nguyen
Ask yourself these questions:
Is the team setup to build features – or to solve real business problems?
Is the team empowered? Product teams exists to solve problems in ways that your customers love, yet work for the business.
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
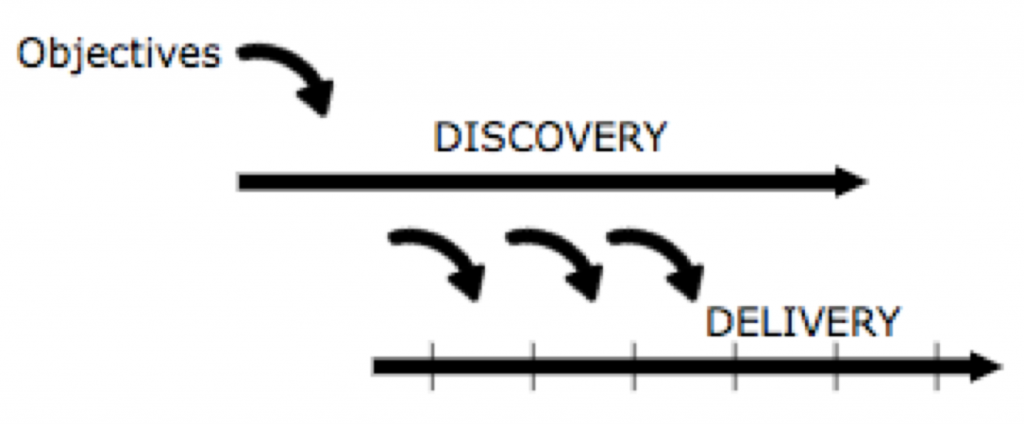
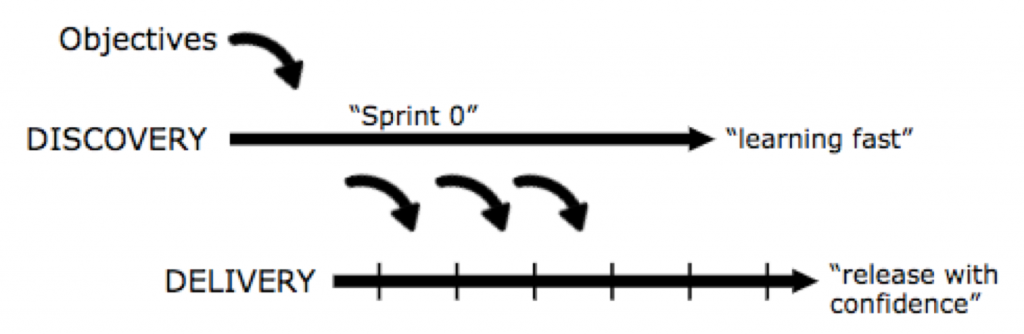
Discovery A rapid series of experiments that enable us to discover solutions to the problems our team is tasked to solve. The results don’t scale -> prototype.
The thinking behind Discovery: “FAKE IT to build the right product”
Cadence: At Discovery we talk 10-30 iterations – per week!
Delivery Building shippable products that provide the necessary scale, performance, reliability, security, and accuracy for us to release, sell and support with confidence. The results do scale -> product.
The thinking behind Delivery: “MAKE IT to build the product right“
Cadence: At Delivery we see typically ½ – 1 iteration – per week.
Discovery and Delivery happen all the time in parallel (dual track agile). Discovery is rarely done by engineers, it’s usually done by Product Managers (PM) and Product Designers (PD). Engineers are busy with Delivery. PM and PD save 1 hour a day for Delivery. Engineers spend ½ hour a day for Discovery. The engineers spend time playing with the prototype, point to critical elements and think about ways to solve specific tasks in a better way.
Who owns what and the cadence of Discovery vs. Delivery
MVP = Minimum Viable Product (better: Test, Prototype). It is the smallest experiment we can devise to try out an idea or tackle a specific risk in product discovery (usually a prototype; never a product!)
Product Market Fit
The smallest delivered product that we can sell, that meets the needs of a specific market.
Innovation
Consistently delivering new sources of value to our users and customers – creating value
Optimization
A low-risk, minor improvement to existing product – capturing value
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
“We need a team of missionaries, not a team of mercenaries.”
John Doerr
Product Teams
The “2-pizza-box” rule indicates a good sizing for product teams: usually 2-10 developers, one product manager and one product designer. One product manager for two teams (or more) is okay as long as there are no more than 10 developers in total.
Spotify is a good example for an organizational setup – teams are named “squads”. Besides the product manager, the product designer and the technical lead other squad-roles are e.g. User Researcher, Delivery Manager, …
Some other companies use the term “triad” to emphasize the product manager / product design / technology lead roles within a team.
A product team is
Small
Durable (formed for many years) – achieve psychological safety; enables relationships – critical for real collaboration and trust
Cross-Functional – allows team access to engineers expertise necessary for innovation
Co-Located
Measured by Outcome – shift from “release and forget” (feature delivered) to outcome (business result delivered)
Empowered
Accountable
Understands Business context
Product Manager
“Intellectually curious, naturally collaborative, plus plenty of grit.”
Lea Hickman
The Product Manager (PM) is responsible and accountable for the results of the product team. The PM must think like an owner. PM’s should be seen as future CEO candidates for the company by the current CEO. If not, the PM is the wrong person.
PM-work should be around 4 hours per day (Spend your time wisely!). Get rid of the meetings! The Product Owner (PO) part is the administrative part of the role and accounts typically to 10% of the work of the PM.
Good
onboarding tool for PM’s: Fill in the product canvas / lean canvas: https://leanstack.com/leancanvas by Ash Maurya, Alex
Osterwalder
Productivity
Hack by Marty: AIRPLANE MODE – put messengers and other instant communication
features into airplane mode if you want
to get work done.
Misunderstanding the role of the PM is the most common reason for the failure of this product development model.
Insider-Tipp by Marty: Subscribe to Ben Thompson’s “stratechery” newsletter (see: https://stratechery.com/).
The PM contributes deep knowledge of … THE CUSTOMER
The PM is
the first person in the company to talk to if anybody wants to know anything
about customers. Marty’s introduction into his first product role: “talk to 15
customers in the US and 15 customers in Europe”. These visits created the base
line for Marty’s knowledge about his customers. He furthermore continued to
visit customers and talk to them. It’s important to memorize: “KNOW THE
UNKNOWN”. Visiting customers is great for networking inside the company and
outside as well.
The PM contributes deep knowledge of … THE DATA
The PM
spends the first 30-60 minutes of a day to look into the available product
data. The PM is the acknowledged expert on product data.
The PM contributes deep knowledge of … THE BUSINESS
The PM knows all aspects of the business model and the underlying business. The PM knows the dynamics, the various stakeholder. Marty intentionally doesn’t say “The PM acts like the CEO of the product” because the way people act is precisely not the analogy. The PM needs to understand the various dimensions of the business – as the CEO does.
The PM contributes deep knowledge of … THE INDUSTRY
The PM is a
domain expert and knows about competitors, trends and does regular
SWOT-analysis.
Skills for a Product Manager
The Product
Manager should attend these academic classes:
intro to computer programming help to understand the developers
intro to business accounting / finance help to understand the business side of the product
intro to statistics / data analytics help to analyze data
Israel has great product teams: everybody has to do military service and in there people learn to solve hard problems under stress.
“Like me, trust me, listen to me.”
Adi Soesan
Adi used to be a fighter pilot in Israel and was kind to people, earned their trust and soon they started to listen / follow her. PM’s need to do the same: be sympathetic, gain trust from stakeholders and people will start to listen to the PM.
Product Designer
“I love creating solutions, and I am optimistic at heart. If you put those together, you get a tenacious-seeming, “there has got to be a way!” to solve any problem mindset, even if it’s a problem I don’t understand at first, or that keeps morphing.”
Audrey Crane
The Product Designer (PD) is responsible for how customers and users experience the value provided by the product. PD’s are typically specialists in interaction design. They’re also not limited to wireframes and do not focus only on online. The PD is doing ideation work and prototyping with the team, is busy with usability and value testing and designs assets for the delivery.
Tech Lead / Lead Developer
The Tech Lead (TL) is the PM’s key partner and overall responsible for delivery. The TL has to have business sense, coaches engineers on the team, is responsible for the holistic view on the technology solution, is an active contributor to product discovery. The TL typically is a senior engineer, an architect or a dev manager.
Other
Roles
Delivery Manager: project manager to remove impediments
User Researcher: qualitative learning
Data Analyst: quantitative learning
Product Marketing: interface between sales and product, usually more closely to sales channels – pricing is typically at product marketing – usually provided through external specialists
Architect
Quality Assurance: manual QA no longer that important – test automation
Delivery Managers take over the project management tasks of the work. The role of a SCRUM Master is part of the Delivery Manager role.
The decision if there is an architect – or not is up to the CTO.
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
The Product Strategy executes the Product Vision and is framed by Product Principles.
“Be stubborn on vision, but flexible on details.”
Jeff Bezos
Product Vision, Strategy and Principles come from the leadership team! When initial founders leave, it’s time for a new Vision by the new leadership team.
Product Vision
The Product Vision paints the picture of what you’re trying to achieve. Typically, the vision is the single-best recruiting tool to attract talent. The vision inspires, is not a spec, is emotional and oversees 3-10 years.
Good example of a well formulated vision from Workiva
“We founded Workiva with you in mind. Our vision has always been to modernize the way our customers manage business data by connecting collaborators, documents, and spreadsheets. The platform allows structured and unstructured data to be aggregated and connected across reporting and compliance outputs, including presentations, spreadsheets, and reports.”
Good example of a comprehensive description of what Adobe wants to achieve with Adobe.revel. (Adobe is a pre-internet company and managed to transform into an awesome company): https://www.youtube.com/watch?v=wZ-dABmfEFw
Product Strategy
The Product Strategy is the path to make the vision happen. The strategy is unique to every company. It is a tool to focus on specific segments (e.g. vertical market, persona, geography, capability). To succeed implementing the strategy it’s more important to have any sequential approach to the segments than on what to focus first. Apple chose the initial customer target group to be the iPod adopters for the iPhone launch. Only the 3rd iteration was targeted at the mass markets.
Tesla’s vision in the beginning was: “… our goal is to accelerate the advent of sustainable transport by bringing compelling mass market electric cars to the market as soon as possible …”. (Tesla’s vision today and an analysis of Tesla’s vision and mission in 2018)
To bring this vision alive, Tesla worked on a risk based product strategy. In a first attempt, they addressed the risk of building a battery that could power a car for 200 miles. Solving this problem produced the Tesla Roadster which is basically an electrified Lotus Elise. The next biggest risk to implement the vision successfully was to design and build a car. That produced the Tesla Model S. The final risk to tackle was manufacturing at scale – for the mass market. This produced the Tesla Model 3 – a mass market car for about 35.000 USD.
Risk #1: build a battery and run for 200mls –> Tesla Roadster (electrified Lotus)
Risk #2: design and build a car –> Tesla Model S
Risk #3: manufacture mass market ready (35.000 USD) car at scale –> Tesla Model 3
Homework for every (!) Product Manager: 1) Work with Google AdWords and book a campaign 2) Drive a Tesla.
Product Principles
The Product Principles describe the nature of the products you intend to create and reflect your beliefs about what’s important. They give guidance in cases of conflicts – e.g. eBay’s product principle: “buyer experience optimization is more important than fulfilling sellers needs”. In cases when the needs of the buyer and the needs of the seller conflict, eBay will optimize in favor of the buyer, because the most important thing eBay can do for sellers is to ensure a large number of happy buyers.
The Product Principles are not obvious, should be top of mind and they’re not laws, but violating should be conscious.
Objectives
“Never tell people how to do things; Tell them what you need them to accomplish and let them surprise you with their ingenuity.”
General George Patton
Objectives & Key Results – OKR
A successful way to make objectives and expectations transparent to a whole organization are OKR’s – Objectives & Key Results. OKR’s are for defining and tracking objectives and their outcomes. OKR bring focus on business and product goals. The Objectives align with qualitative business and / or product goals and are synchronized with the overall strategy. The Key Results are quantitative measurable outcomes working towards the Objectives. OKR’s do replace feature roadmaps and ensure we’re working on the most important things. They also allow High Integrity Commitments for time critical objectives.
Aspirational results are meant to inspire thinking big Objecitve: “Speed up customer onboarding” Team: “with 50% confidence we’ll manage to get it down from 60 to 20 days“
Commitment results are meant to be counted on Team is aked for a High Integrity Commitment: do enough research to figure the 4 risks (value, usability, feasibility, viability) to make the commitment
OKR’s – Key Points
Set the objective first, then the measurement
Focus on outcome, not output
Focus on organizational and team-level OKR’s
Make them public, visit your progress at least weekly
Focus on a small number of OKR’s
If the team misses all objectives, don’t fire them. Sit down with them an do a post-mortem – understand what happened and make them accountable.
Example –
organizational OKR’s
Grow the core business
‣ Total revenue + 10% ‣ $XX from new Partnerships
Diversify revenue
‣ > 30% revenue from non-core business ‣ Product-Market-Fit (PMF) on one new expansion vertical
Improve customer satisfaction
‣ Customer churn < 5% ‣ NPS > 55
Example – Team Level OKR’s (B2B)
Discover our core customer value (PMF)
‣ 12 new customers on new product ‣ 8 reference customers (>4 new)
Dramatically improve end-user engagement
‣ > 80 of licenses sold active after 30d ‣ avg. 3+ logins per user per week
‣ Customer can deploy PoC in < 5 mins ‣ >90% automated test coverage ‣ Reduce latency by 50%
Example –
Team Level OKR’s (B2C)
Increase the organic user base
‣ Increase per-day views by 20% ‣ 10% new users from viral referral
Improve end-user engagement
‣ Avg. 3+ logins per user, per week ‣ Avg. 60+ minutes per user session
Simplify onboarding
‣ Reduce avg. to 20 sec ‣ Increase task completion to 90% ‣ Retention +20%
Dramatically up-level our infrastructure
‣ Automate build process ‣ > 90% automated test coverage ‣ Reduce latency by 50%
Don’t do this with OKR’s
Don’t crash your organization – it needs to be ready. OKR’s as a leadership instrument are great, if the surroundings are right. Successful OKR implementations need the right culture, they need companies with empowered employees, with empowered teams. If applied at any other organization, the culture will clash.
Don’t do individual or functional OKR’s. Focus on organizational and team-level OKR’s.
Don’t link financial compensation to OKR’s – NEVER. Every product person should have equity in the organization. Incentive based compensation is not good for people’s motivation.
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
Don’t release anything without instrumentation! NEVER!
Marty Cagan
Collect product data as early as possible. Don’t save on data, collect generously. Make the information available freely internal to your organization – share data widely. Share findings in your data, be honest and report good news as well as bad news.
Product data inspires new product work, measures progress and allows to understand customer behavior. Most important, product data is the fundament to allow informed decisions. Collect data, find evidence that ideas work and let data influence your decision making process.
What can be
measured?
Behavior (click paths, engagement)
Business (active users, conversion)
Financial (average selling price
(ASP), billings, time to close)
Performance (load time, uptime,
crashes)
Operational costs (storage, network,
computing)
GTM costs (acquisition, programs)
Sentiment (NPS, C-SAT, exit surveys)
External sources (PR mentions,
comments, social media)
Example – Experience Metrics – following the H.E.A.R.T. Framework
For a broader discussion of the H.E.A.R.T. Framework follow the link.
Happiness
‣ actual NPS ‣ % satisfied users
Engagement
‣ % active users of X / time frame ‣ avg. number key action per user ‣ avg. time between key actions
Adoption
‣ adoption rate ‣ time to first action
Retention
‣ retention rate ‣ mean time to churn
Task Success
‣ completion time ‣ error rate
One key criterion for B2B services to move away from on-premise to cloud based services is that instrumentation comes basically for free. B2B has to relax on security, safety and privacy concerns – or find ways to implement their high standards in cloud services – but these businesses get a lot of analytics from the cloud provider – they know, what’s going on.
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
Certain key prerequisites need to be in place to scale a product management organization successfully.
Strong leadership and management The leadership team has defined and live their role role of management & leadership in the agile customer centric organization. Not less management is needed – just better, different.
Clear vision, strategy and principles An organization bigger than 10 teams needs a clear vision, strategy and principles for orientation.
Coordinated objectives The objectives within a team and the whole organization need to be aligned with the vision and strategy.
Scalable architecture A scalable architecture follows a good / clear product vision. Technical debt is typically a result of growth – a system designed for 5m users can not stand 50m users. Time to rethink! Addressing Technical debt is in the accountability of the CTO and typically referred to as a business continuity issue. 20% of engineering capacity usually goes in Tech debt prevention / reparation. If the backlog is empty, switch to Tech debt removal work. Resolve Tech debt step by step – rewriting is typically the worst answer to this issue. It normally takes twice as long than anticipated. Technical debt killed Netscape and Friendster lost the battle to Facebook due to technical issues.
Team structure The higher goal behind team structure is to create autonomous teams with minimized dependencies – make them work independently for maximum execution capabilities.
Delivery managers Delivery managers identify impediments and remove them. They are a mixture of project managers and SCRUM Masters. Typically, Accenture is a great source of talent for Delivery managers.
Constant evangelism Repeat, repeat, repeat. Constant repetition and sending the product management messages, beginning with the vision over the mission towards hypothesis driven and value orientated work processes, is critical to scale product – especially in big companies.
The role of Leadership
“The combination of curiosity, respect, and kindness combined with crazy work ethic will take you anywhere you want to go.”
Stacee Santi
Leaders in successful organizations are coaches. Their primary goal is to grow people, to support them in succeeding. Below listed are focus points of leadership roles within the product organization.
Product Leaders
‣ evangelism ‣ coaching
Design Leaders
‣ design language ‣ standards ‣ coaching
Engineering Leaders
‣ architecture ‣ standards ‣ coaching
Delivery Manager Leaders
‣ commitment ‣ dependencies
Data Leaders
‣ data tools ‣ common KPI language
At Spotify, any leader within the organization could deliver the coaching function. It’s every leaders’ goal to grow people. Marty mentioned that Christian Idiodi (https://www.linkedin.com/in/cidiodi/) is exceptionally good at growing product people.
Structuring
Product Teams
The Product and Technology leads need to come up with an answer to the question on how to structure product teams. Should the organization have vertical teams focusing on specific business topics? Horizontally layered, with frontend, backend and data teams? A mix of both?
A typical setup includes vertical focus teams mixed with Common Services Teams (CST). The CST take special care of architectural topics, scalability and performance and they develop shared services. The PM role is typically more technical focussed and the customers are usually other product teams. Usually, there is no design role needed. Discovery happens in conjunction with other product teams.
The overarching goal of this structuring exercise is to create a setup with minimized dependencies to create fully autonomous teams. Here are some questions to ask during the process:
How many product teams?
What is the scope of each team?
Dependencies between teams?
Compatibility with architecture?
What is the size of each team?
What expertise is required for each?
Level of autonomy of each?
Code ownership and dependencies
Setting up multiple teams with defined scopes raises another important question – who owns which part of the source code. Typically there are two models – a team owns their code (“request-model”) or the code is owned by everybody (“open-source model”). The request-model implies a higher degree of dependencies between teams needing to work cross-domain. If one team depends on changes done by another team the first team can no longer work fully autonomous. With the open-source model every team can change any part of the source code. This model needs higher standards when it comes to source code management and testing. Marty discusses this on his blog “Autonomy vs. Ownership”.
Amazon’s way to setting up teams
Set vision & goal
Define architecture
Form teams around architecture
Set clear accountability and ownership
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
In 2014, Facebook changed its mantra for developers from “Move Fast and Break Things” to “Move Fast with Stable Infra”. Only moving fast doesn’t bring the business benefit home. At a certain tipping point the engineering organization introduces more “broken things” than they’re able to fix in the long run – speed of the organization stalls or declines.
The new mantra relies on two cornerstone principles Release Quickly and Often and Release with Confidence. Releasing quickly and often leads to small and quick iteration cycles. These foster quicker learning and fuel innovation. Releasing with confidence keeps damage away from your brand, your revenue streams, your customer base and your employees. Confidence refers to accurate software, reliable and well-performing releases, scalable software and released software without privacy or security concerns.
A good example of a well performing product organization is Google Search. They run a total of 15 product teams. They work on over 2.000 product ideas – no product optimizations – in Discovery with less than 500 built in Delivery. The ratio is 4:1 – 4 ideas in Discovery, 1 get build. They aim for 10.000 ideas in Discovery with less than 500 being built. See “Rigorous testing” from Google for further information. Google mentions in this article they did 595.429 Search quality tests, 44.155 Side-by-side experiments, 15.096 LIve traffic experiments resulting in 3.234 Launches – in 2018 alone!
The industry benchmark in well operated digital product development organizations is to kill 75% of ideas in Discovery. If not a minimum of 50% of the ideas are killed then it’s Design, not Discovery and a clear signal of a malfunctioning organization.
Issues of Conventional Agile
“Agile is all about building and delivering software, but it says almost nothing about how to come up with a valuable product backlog.”
Marty Cagan
Agile software development helps a lot, but doesn’t say anything about building a valuable backlog. It is completely blind on the value side, answering the what should be built. Marty discusses a solution to this issue – dual-track agile – on his blog.
Issues of Conventional Agile:
Thanks to agile, teams move faster. But agile doesn’t provide teams with a valuable goal.
Moving fast without a goal leads to feature chasing. The goal of agile is to produce more output, not necessarily more business results or more value. This is especially tricky with mature products where removing features might provide more value to the business and customer (use A/B testing to understand the value). Also in mobile products more features most often fail – they distract more since there is too less inventory – and finally don’t have an impact.
Engineers are most time only coders and don’t contribute further more to the overall value generation process.
In agile it’s very hard to predict any dates and make commitments since it’s based on user stories only.
UX Design suffers because there is simply no place for UX in agile. The sprint iteration doesn’t reserve time slots for UX to work as part of the iteration. If engineering is ready to go UX should be ready as well but usually start right now to work as well.
The architecture of the system suffers as well. Fast moving teams produce more technical debt. Without really knowing good ways to solve an issue, suboptimal long-term solutions are implemented and increase the need to repair architectural decisions.
The rest of the company – marketing, sales, customer support … are brought in too late into the process.
Salesforce rolled out agile by the book about 15 years ago. As a consequence the whole UX & Design team threatened to quit because conventional agile didn’t include UX & Design at all. So, after some discussion Salesforce included UX & Design in their agile working model and pivoted from the Conventional Agile approach.
Continuous Discovery and Delivery – Dual Track Agile
“Discovery, by definition, means you don’t know the answer when you start.”
Ed Catmull, Co-founder of Pixar
Parallel Product Discovery and Delivery – Dual-Track Agile
“Dual-Track Agile” emphasizes the parallelism of Product Discovery and Product Delivery. They happen all the time in parallel. The Discovery track is all about fast learning, building a validated product backlog. Delivery is all about creating software that could be released with confidence, shippable software. The Discovery track is led by Product, Delivery by Engineering.
Product Discovery provides missionaries with purpose. In Discovery, the key risks are addressed and meaningful answers to these questions give guidance to the team. The given answers are all validated, there is enough evidence proving it will work.
Will they buy it? (Value)
Can they use it? (Usability)
Can we build it? (Feasibility)
Can our stakeholders support it?
(Viability)
Bonus question: Should we build it?
(Ethics)
When all critical questions have good and validated answers, describe what to build in Delivery. Therefore, use e.g. JIRA stories with prototype and UX design (prototype-as-spec).
It is, however, not needed to validate all risks all the time in discovery before putting anything into the backlog. The trio of people (PM, PD, TL) does the risk assessment (takes 5 minutes talking). Pick and choose the techniques to validate if needed. Don’t be religious about the process.
Example: At ebay, one base assumption is: create a safe place for transactions. This assumption is the root cause for the overall reputation system within ebay.
Discovery and prioritized backlogs
“Don’t prioritize your backlog – simply try thousands of ideas!“
Marty Cagan
Follow only those ideas in favor of the overall business objectives. Don’t spend too much time thinking about them, just try them. One iteration in Discovery means: One new idea or another approach to an older idea.
Put the ideas that work into the product backlog. If the product backlog is empty switch to “feed-the-beast” mode and allow the teams to work on e.g. technical debt or other meaningful tasks. If the product backlog is too full – means more than 2 weeks of work – you have a rotten backlog. Here, ideas will no longer be valid or well memorized if too much time has gone before going into Delivery.
Good example for a Product Discovery phase and how fast they were collecting evidence and pivoting: BMC Business Modell Competition – First Place Winner: Owlet (https://www.youtube.com/watch?v=f-8v_RgwGe0)
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
“The most important thing is to now what you can’t know.”
Marc Andreessen
1) We know
we can’t count on our customers to tell us what to build
Avoid focus groups. Customers don’t tell you what to build because they simply don’t know what is possible with latest technologies in place. Furthermore, they don’t know what they actually want until they see it – hence use prototypes during your customer feedback sessions. Customer-facing product teams go 3 hours per week to see the customers. “Customer inspired – customer enabled”.
The iPhone wouldn’t happen with focus groups. Skype hired Nokia, Motorola and Apple people and they compared the different approaches to innovative products. It took 3 ½ years to build the iPhone. Nokia and Motorola were doing focus groups when Apple started the iPhone. Palm has just released the Treo with Touch Screen and people didn’t like it. The focus group gave clear indication to skip the touch screen. So, at the time, Motorola and Nokia decided not to build phones based on touch screens. Apple hat a vision – the iPhone vision – “Build a touch screen powered phone.”
2) The most
important thing is to establish value
Value for customers, creating value for customers. Typical product roadmaps line up features. The underlying assumption of feature roadmaps is that there’s value in the feature and business viability is granted. But that is typically not true.
3) We
recognize that engineering is hard, but the user experience is often even more
difficult, and more critical to success
This is especially true at B2C companies – 50 engineers and 2 visual designers don’t work out. The experience and value perceptions created at the customer is vital – UX is more critical to success than technology.
4) We
recognize that functionality, design, and technology are inherently intertwined
5) We
expect that most of our ideas won’t work, and those that do will require
several iterations.
Many
iterations never make it beyond us – the team; they’re simply stopped
internally in early stages.
How many
iterations should one follow before skipping the idea?
Depends on the importance of task
Ask yourself: “Are you still learning with every iteration?”
Change the approach to the problem (e.g. churn)
Timebox: 2 days for one approach
Avoid the “fall-in-love”-pitfall with design: use less than 2 days for design before result is shown to users.
Example: Ceramic class separated into two groups with separate goals. The first group should build one high quality pot. The other group is instructed to build as many pots as possible – it’s only the weight that counts. The second group won the quality challenge because of practice! The first group wanted to produce the “perfect” pot but failed with just 1 mediocre pot.
6) We must validate our ideas with actual customers
Go out of the building, talk to real customers. It’s valuable to start with your team mates, colleagues, people working inside your company – but finally, you need to get the opinion of your real customers.
7) We
validate our ideas as quickly and cheaply as possible
Possible
even in hardware: 15 iterations per week. Google Glass team build an engagement
model prototype and improvised a futuristic user interface with simple
technologies. They quickly learned about a key problem: shoulder sourness and
skipped the key assumption for success.
8) We use
both quantitative and qualitative techniques
Quantitative:
What’s happening?
Qualitative:
Why is it happening?
Example: Etsy switched to endless scrolling from pagination. The A/B-Test showed people buying less. The qualitative analysis showed: there were simply too many cool things to buy and people couldn’t decide – paradox of choice
9) We must
validate both technical feasibility and business viability in product
discovery, not after
Include
engineers ways before planning. They need to be involved and see what to build
before sprint planning.
10) It’s
all about shared learning
Shared learning happens all the time in a co-located team. Discussions over coffee, exchange of opinions at the work-desk, discussions are all around. Furthermore, allow engineers 30 minutes playtime with the prototypes each day to let them express their concerns and start having good ideas on how this could be build.
With a distributed team in place, schedule a 30 minutes meeting every day to allow the exchange of ideas, to give engineers air time with the prototype and help them understand the ideas behind.
Big companies run innovation labs for product discovery. But good ideas never materialize due to the separation of Discovery and Delivery.
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
Don’t use these discovery techniques for bug fixes or optimization. They’re meant for real product discovery work, identifying and foremost validating big new product ideas.
1) FRAMING
Framing is the activity where the problem space is defined and the relevance of the problem at hand gets better understood. Do not spend too much time in framing.
The Opportunity Assessment is enough 90% of the time.
What business objective are you focused on? typically one of the OKR objectives
How will you know if you have succeeded? typically one of the OKR key results
What problem are you solving for our customer? do you really know it’s a problem?
Who are you solving that problem for? typically a target market or persona from the strategy
Internal Press Release
The Internal Press Release is not intended to go public – it’s for internal use only. The anticipated audience is new product’s customers – actually it’s the team, management and stakeholders. It’s typically 1.5 pages maximum and written in “oprah-speak”, not “geek-speak”. Sometimes, 3-4 pages of FAQ for anticipated questions are added. The structure of the internal press release looks like this: heading, summary, problem, benefits, quote from you, customer quote, closing / call to action
Amazon uses Internal Press Releases for big ideas / efforts (e.g. site redesign or moving into new country).
An alternative to the Internal Press Release is the Happy Customer Letter describing the benefits for a customer written by the customer and the CEO-letter describing benefits for the company.
An alternative to the Lean Canvas is the Opportunity-Solution-Tree. It is introduced by Teresa Torres at her Mind The Product Talk 2017 in London “Critical Thinking For Product Teams“.
User Story Mapping helps to visualize and deconstruct the problem or solution space. It provides an holistic view and gives context. Through the collaborative process it encourages shared understanding, identifies holes in thinking and improves planning and estimates. Furthermore it heavily influences prototypes and actually helps to scope releases for the product.
The basic idea of the Customer Discovery Program is to discover and develop a set of reference customers in parallel with discovering and delivering the product. At the stage where the reference customer signs up for the program there is no product ready to be delivered. The Customer Discovery activity makes only sense for real big efforts, absolutely not for features. Serious enterprise customers are very likely to sign-up because they’re burned by the practices of Oracle, SAP and the likes – sell and run.
The reference customer bought the product without any side deals, runs the product in production and loves it enough to tell the world about it. In Customer Discovery, we’re looking for “Earlyvangelists”. An Earlyvangelist is best characterized by these criterion:
With the Customer Discovery Program it’s simple to tell if product / market-fit is reached: achieved if 6 reference customer for a single market segment (e.g. industry, geography, …) are found. The product / market-fit product is the smallest possible product that meets the needs of this group. If you find only 4 customers or less this means the product market fit is invalidated and a pivot is needed. Work with 5-6 companies – and not more than 8. Talk to as many as possible – e.g. 50. Select only the most attractive for the Discovery Program, the other customers go into the beta program. Agree with the selected companies to be a discovery partner and ensure the right level of access to people and input. Agree with them to become a public reference if they like the delivered product.
In Enterprise business the goal is to find a single product solution that fits all discovery partners. Again, it’s important that all partners are from one single market segment. In Consumer services you should identify 8-20 Earlyvangelists and agree with them on regular phone calls to synchronize.
Examples for customer discovery: OpenTable (SMB), Symantec (Enterprise), Bazaarvoie (B2B2C), xoopit (Platform Services), Apple (internal tools), BarkBox (Consumer Service)
Customer interviews are needed to understand your customer, to get rid of assumptions and start working with facts. Marty summarizes the value of interactions with customers in his post “Don’t talk to customers?“. Below are the key questions to answer:
Public API’s (let others innovate on your product) – be aware of bad usage: Cambridge Analytica + Facebook
Hack Days (directed and undirected)
Data Spelunking (Hackathon on data)
4. Prototyping
The prototype should minimize the time by factor 10 to provide something to look at. See more on prototypes at Marty’s blog “Flavors of Prototypes“.
User Prototypes
User prototypes are created very fast and lightweight by nature. The prototypes are used for value testing with a consumer or customer to quickly gather feedback on both, usability and value. Low fidelity user prototypes are used for team internal iterations. Use high fidelity prototypes to show-case internally to executive people. The prototype is usually created by the Product Designer with support from the Product Manager. Ideally, when finished, the prototype could be used as a specification for the Delivery process – “prototype-as-spec”.
Paper prototypes are too limited by nature, use wireframing tools (e.g. balsamiq, axureRP, proto.io, FLINTO, UXPin, marvel, invision, Adobe XD) instead. They allow interactions with the prototype and are no more effort to build.
Feasibility Prototypes
The feasibility prototype validates the solution approach. Usually, the prototype is build by engineering to gain further insights on the implementation and test technical (e.g. scalability, performance) risks. The prototype might not be more than a code fragment or a successful validation of a 3rd party software or API integration. It may also happen that product people are not involved in the prototype at all.
Live Data Prototypes
The purpose of the live data prototype is to collect further evidence pro or contra a product decision. This prototype is more expensive to build than the user prototype, but still far less than the actual product. The prototype is not the real product, it’s usually 5-10% of the real product. It includes quantitative a/b-testing but also qualitative testing and is based on real data. A small amount of real traffic could land on the prototype to collect data. Engineering is typically needed to create the live data prototype within 2 days up to 2 weeks.
A lot of people get excited when they see the live data prototype and tend to confuse the prototype with the real product. But there’s still a significant difference between production ready software and the live data prototype. The real product needs:
All required use cases
Instrumentation / analytics
Test automation
Scale and performance
SEO work
Maintainability
Internationalization / localization
A good example of a live data prototype is Amazon’s “Frequently bought together” feature. The idea of building the features was rejected by SVP Marketing. So, strong evidence was needed because it was simply too expensive and risky to productize the feature without further evidence. So, the team decided to build a live data prototype with a small amount of real traffic in a specific product category. The prototype was a/b-tested and the collected data provided a significant uplift in business KPI’s. This is a great example of a high-integrity business case.
Hybrid Prototypes
Hybrid prototypes mix those elements needed to tackle the specific risks at hand. They blend various techniques and are mainly limited by your own creativity.
A good example of an hybrid prototype is Zappos. Zappos solved the problem of female shoppers to buy fashion shoes online. They defined and understood their personas and their key problems with shopping online: 1) returning goods 2) no timely delivery 3) not knowing the size 4) bad product images. Zappos prototyped a potential solution to the persona’s problems by mixing a variety of prototypes: user prototype (appealing front-end), live data prototype (product catalogue and images) and the “Wizard of Oz” (buying the shoes at the shop over the street and delivering to customer). Most important was: the users shouldn’t recognize the prototype character of the solution. Zappos controlled the amount of traffic via AdWords and made sure they could handle the manual part. So, with this mixture of prototypes – that for sure doesn’t scale – they could validate demand, value and usability.
Testing Product Ideas
“Prototype as if you know you’re right, but test as if you know you’re wrong.”
d.school
Marty writes in his blog about “Prototype Testing” more detailed on the various ways to testing.
5. Testing Usability
Usability testing includes interacting with customers, getting their feedback. For the test session, have the prototype ready – up and running and focus on the prepared questions to understand if users have issues using your product. The session may be conducted at your office, the customer’s office or at a mutual convenient location (e.g. Starbucks) or – if not possible – remote via video conference.
Recruiting users in B2B context is done via the customer discovery program, in B2C via AdWords. AdWords allow acquisition of users based on keywords and / or geo-targeting. It’s the most cost-effective solution and easy to stop and restart again. Payment is entirely based on performance.
6. Testing Value
Testing value focuses on three aspects: testing demand (is this really a problem?), testing efficacy (how well does the product solve the problem?) and testing response (how excited are the testers?).
Testing Demand
Testing demand answers the question if people are willing to use the product, if they understand the value and see the product solving a real problem they have. Marty talks more about Desirability Testing on his blog about “Product Validation“. Some techniques for demand testing are described below
Fake Door Test
A fake door test fakes a product feature for the customer. If the customer acts with the fake product a thank-you-message is displayed and sometimes contact information is collected. Furthermore, nothing happens. The goal of the test is to collect data, to measure the click-thru ratio. More information on the fake door test can be found here: http://learningloop.io/plays/fake-door-testing.
Landing Page Test
A landing page test pitches product features, products, product lines or other promises to the customer combined with an explicit call to action. Push traffic on the landing page via e.g. AdWords or other comparable methods. Now, measure the conversion – how many people do actually interact with the landing page and are interested enough to follow the call to action? With the click, nothing happens with the customer other than a friendly thank you message and sometimes the question for contact details. More information on the landing page test can be found here: http://learningloop.io/plays/spoof-landing-pages
Explainer Video
The explainer video shows a high fidelity prototype at work. It’s basically a video of a product demo. It is then distributed and measured like the landing page test above. The goal, again, is to measure demand for the demoed product. More on the explainer video: http://learningloop.io/plays/video-demo
Kickstarter Testing
A great way to test a product idea without jeopardizing your brand is to test demand on kickstarter.com. Just place the product idea at the crowdfunding platform as a “nobody”. If the idea creates enough buzz it’s worthwhile a further investment, if not it can be dropped silently without creating any noise. Read more on the idea from Mark Dwight “How to Kickstart Your Market – Why even established companies can use crowdfunding.“
Qualitative Value Testing
“Find everything that’s wrong with the product and fix it; Seek negative feedback.”
Elon Musk
Qualitative testing explains why it’s working or not, it gives insight why something is happening or isn’t. It doesn’t try to prove anything. You won’t get the answer from any one user test; every single test provides another piece of the puzzle. It’s important to test with real users and customers to judge the value.
Qualitative value testing is done with prototypes or the real product. It provides insights from usability and value perspective. On top it usually provides unexpected insights from the customer. It’s typically done fast and cheap. To really understand how much customers value the product, various questions or tests can be conducted:
Payment – will they pay for it? credit card information, pre-order form, letter of intent (in B2B)
Reputation – will they recommend it? NPS, introduction to peers or the boss, public reference
Time – will they meet again? Will they invest their time? agreement on follow-up meeting, non-trivial trial
Behavior – will they switch from their current solution?
Quantitative Value Testing
“Features are not inherently valuable. The value for our customers is only realized when a feature fulfills a need. It’s only realized for our business when we see the results of our work move the needle. That’s why we need to concentrate on the outcomes over the outputs.”
Quantitative value testing can provide evidence or even proof that something truly works – or isn’t. It generally can not explain why it’s so. It’s done to get a clearer picture on the impact on your revenue, your brand, your customers and also your employees.
Quantitative testing can be done with the existing product – or a live-data prototype – in an A/B testing setup on a certain amount of your traffic. Alternatively, it could be done with a limited amount of your customer through invitation. In a B2B scenario, you’d use your existing customer relation via the Customer Discovery Program to get exposure of the test to people.
A good example for a quantitative value test is Spotify’s “Discover Weekly” feature. Data collected in an A/B test was compelling enough to fully implement the feature. The launch-ready implementation included some big hurdles and a lot of effort on the data crunching side. So, it was well worth the effort to test – before – putting the feature in Delivery.
7. Testing Feasibility
Testing feasibility mainly addresses technical concerns – are we able to build this at all? To test feasibility it’s important to create prototypes that focus on the key areas of concern. Emphasize speed of learning over reuse of the written code. Your Tech people need to answer these questions:
Do we know how to build this?
Do we have the skills on the team?
Do we have enough time?
Do we have the right architecture or
components?
Do we understand the dependencies?
Will the performance and scale meet
our needs?
Do we have the infrastructure to
test and run this?
8. Testing Business Viability
Business viability – does this feature / product fit with our business? – needs to be addressed to be successful within the own organization. Your stakeholders (e.g. Senior Executives, Sales, Marketing, Finance, Legal, Security, Business Operations, …) need to be informed regularly, you need to earn their trust. Have discussions with them and make them feel you understand them – but remember: everyone has a voice, but not a vote! Try to engage individually with them, group meetings can cause a lot of damage and are harder to handle. When talking to your stakeholder, have your data ready – data always beats opinions. And read the signs during the meeting – differentiate between stop signs and yield signs.
Techniques you can use for a stakeholder meeting is typically a high fidelity user prototype and / or a product walkthrough.
This blog post is part of a series. It summarizes my personal notes of the workshop held by Marty Cagan “How to Create Tech Products Customers Love” from 5th to 6th of June in 2019 in San Francisco.
We use cookies to optimize our website and our service.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.